Deploy de OMniLeads Onpremise en Alta Disponibilidad¶
En esta seccion se exponen conceptos y procedimientos para el ejecutar la aplicacion en alta disponibilidad.
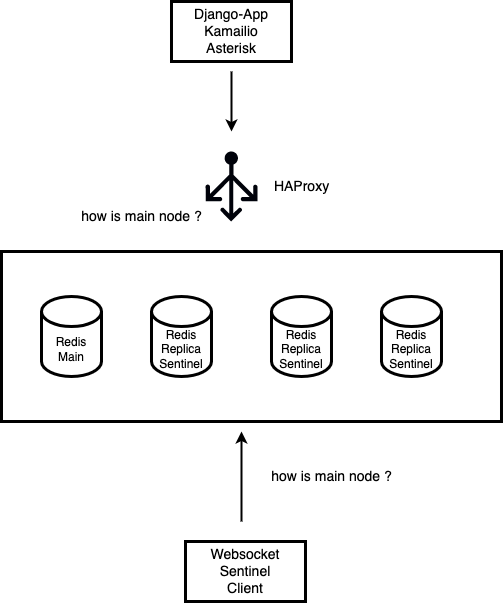
En lo que concierne a la parte conceptual debemos revisar la arquitectura propuesta:
Tal como se plantea en el esquema los componentes se encuentran distribuidos de la siguiente manera:
Redis¶
Para la confeccion del servicio de Redis en HA, se despliega un cluster basado en Sentinel. A muy grandes rasgos, es nos permite mantener un UNICO nodo apto para realizar operaciones de escritura y luego tres nodos extras en modo de replica y solo lectura. Estos tres nodos cuentan con el servicio de Sentinel corriendo y es este ultimo quien a traves de pactar un quorum de 3, resuelve cual de los nodos de replica asume el rol de nodo principal en caso de una caida de nuestro nodo principal.
El cluster de redis no implementa ningun tipo de direccion ip virtual que se mantenga sobre el nodo principal, por lo que la determinacion del nodo principal (el unico que puede procesar escrituras), se necesita resolver del lado del cliente. Hay varios componentes (asterisk, kamailio, django-App y Websockets) que utilizan a Redis, por lo que a la hora de determinar cual de los nodos redis esta disponible para escritura, es decir conocer cual es el main, se utilizando dos aproximaciones:
- HAproxy: los componentes Asterisk, Kamailio y Django-App se basan en Haproxy. Es decir directamente declaran la direccion de red de HAproxy en sus variables de entorno, por lo que las peticiones salidas de dichos componentes tienen en realidad como destino Haproxy, y es este ultimo quien se encarga de redirigir las operaciones de escritura sobre el nodo redis main, a partir de sus posibilidades de proxy TCP.
- Sentinel client: el componente Websockets de OMniLeads recurre a la implementacion de un cliente de redis sentinel. Osea que la inteligencia para determinar cual de los nodos redis es el main es implementada por dicha libreria.
Por lo que a continuacion debemos ser capaces de desplegar cuatro instancias de Redis a partir del script de instalacion disponible en el repositorio:
curl https://gitlab.com/omnileads/omlredis/-/raw/master/deploy/first_boot_installer.tpl?inline=false > first_boot_installer.sh && chmod +x first_boot_installer.sh
Entonces con el script de instalacion disponible en cada uno de los nodos, se avanza con la configuracion de los parametros. En esta seccion solo vamos a poner enfasis en la variables de instalacion para HA. Ya que las demas estan explicadas en la seccion Deploy del componente Redis.
Descomentamos entonces todos los parametros de HA. Se deben considerar dos tipos de nodos, a la hora de plantear las variables de instalacion.
Por un lado cuando se despliaga EL nodo main:
# -- Remove comments in case of high availability deployment
export oml_deploy_ha=true
# -- HA instance Rol: main | backup
export oml_ha_rol=main
# -- hostname or ip of master cluster instance
export oml_master_ip=10.10.10.10
# -- master redis port for monitor cluster
export oml_master_port=6379
Y por otro lado tenemos a LOS TRES nodos replica:
# -- Remove comments in case of high availability deployment
export oml_deploy_ha=true
# -- HA instance Rol: main | backup
export oml_ha_rol=backup
# -- hostname or ip of master cluster instance
export oml_master_ip=10.10.10.10
# -- master redis port for monitor cluster
export oml_master_port=6379
Donde para los tres restantes nodos del cluster se implica la misma configuracion de variables.
10.10.10.10 es tan solo una IP ejemplo. Este parametro debe coincidir con la direccion IP o hostname de nodo main del cluster.
Finalmente se asume que se han instalado 4 nodos con redis (uno main y tres de replica) a partir de la ejecucion del script en cada nodo.
Comprobaciones luego de instalar:¶
Para comprobar el estado del cluster de redis, simplemente se acude a la utilidad de linea de comandos redis-cli.
Sobre cada nodo del cluster podemos ejecutar el comando:
redis-cli info replication
Esto tambien se podria lanzar desde un cliente redis local apuntando con el parametro -h hacia la IP de cada nodo.
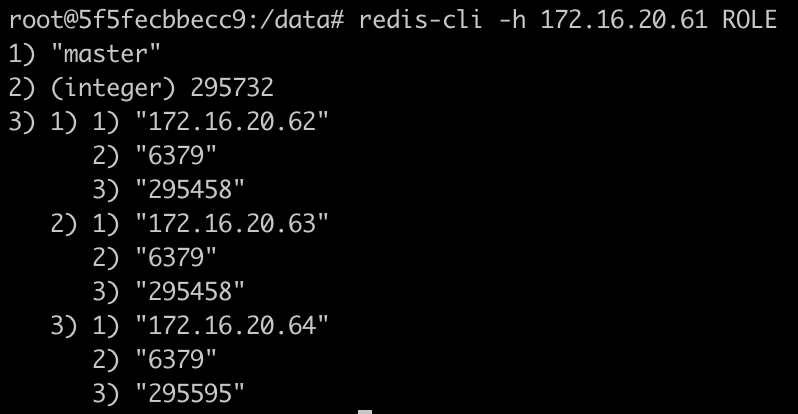
Consulta del ROL a un nodo main.
Como se puede ver en la imagen, desde un redis-cli utilizando el parametro -h para apuntar a la direccion de cada nodo redis, se puede consultar el ROL de cada nodo.
A la hora de consultar el resto de los nodos tenemos una salida similar a la figura:
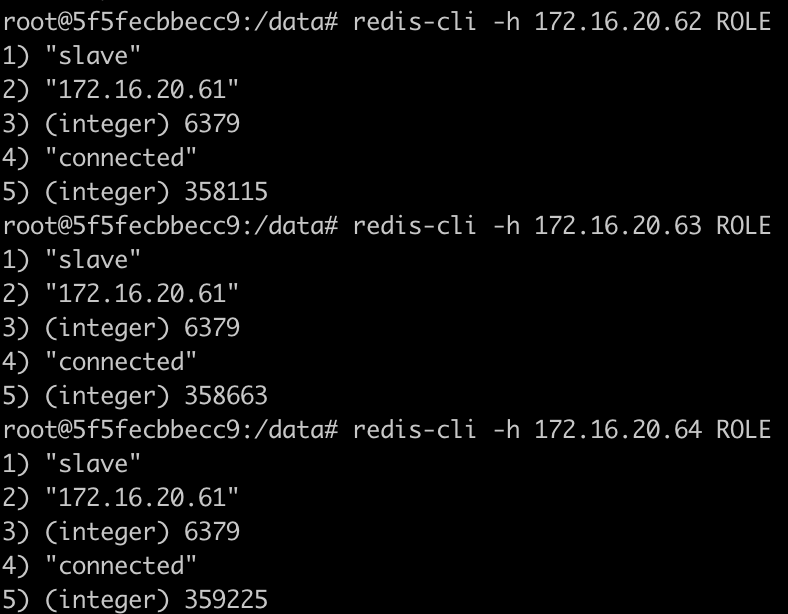
Nota
El comando redis-cli es una utilidad de linea de comandos. Podra disponer de la misma en su maquina de trabajo o bien acceder por SSH a cada una de las instancias de Redis para realizar la comprobacion.
Comprobación de Redis Failover¶
Para forzar un failover y comprobar si el cluster funciona, se puede proceder con el apagado del nodo main, observacion del log /var/log/redis/sentinel.log y posterior interrogación sobre el ROL cada nodo.

Finalmente al interrogar a los nodos redis, se puede comprobar que uno de los 3 nodos de replica asume el rol de main:
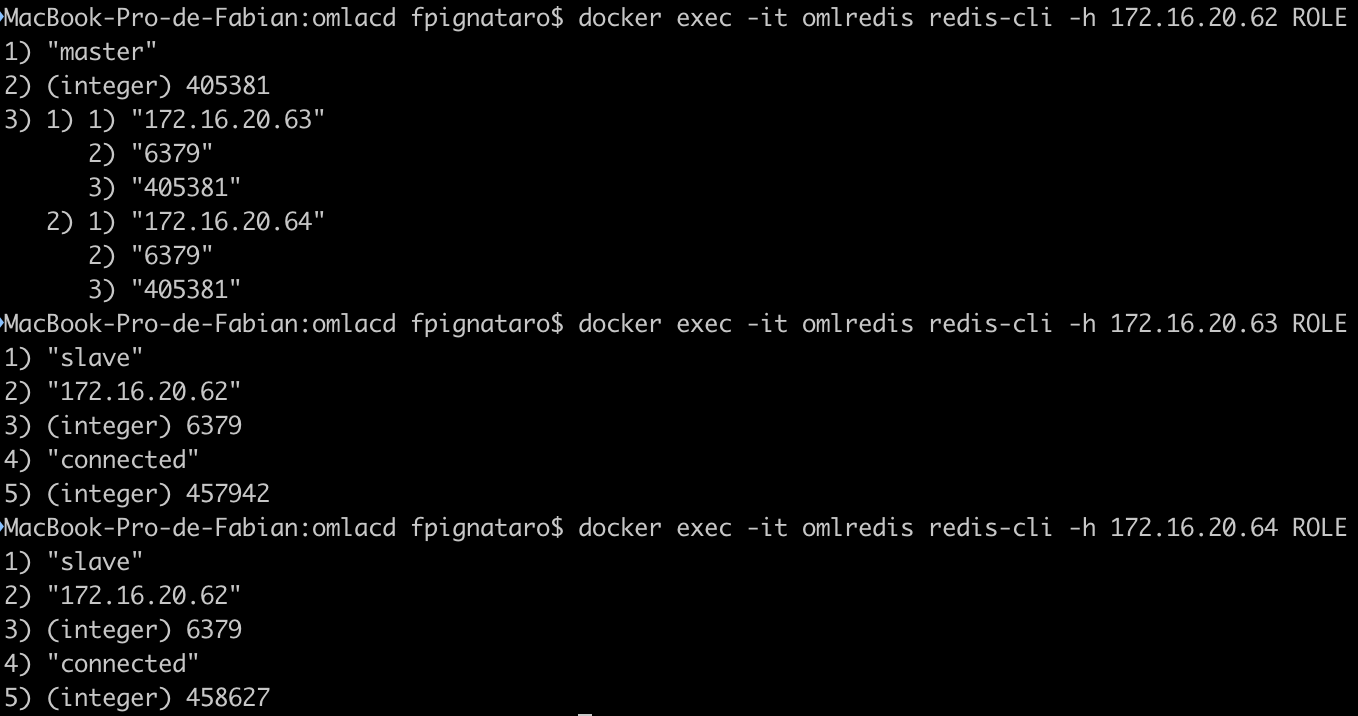
Finalmente con el cluster Redis constituido se avanza en el siguiente componente.
PostgreSQL¶
A la hora de confeccionar un cluster de PostgreSQL se opto por aprovechar la funcionalidad de replicacion, mientras que se acudio a repmegr como cluster manager, es decir asumiendo la responsabilidad de monitorear al nodo principal, lanzar un failover en caso de ser necesario y todo lo inherente a la consistencia del cluster y sus nodos. Finalmente existe un script devenido en servicio de systemd el cual se encarga de la gestion de las IPs virtuales de RO y RW.
Por lo tanto se trata de dos nodos PostgreSQL, uno definido como main con el servicio activo y el otro como replica. Existe una direccion VIP (Virtual IP) para operaciones de escritura y otra para operaciones de solo lectura. Ya que el nodo que oficia como main admite escritura mientras que el nodo replica solo lectura. Por lo tanto a la hora de definir las variables de entorno de conexion a PGSQL tanto en Asterisk como en Django App, se debe tener en cuenta el hecho de proporcionar la VIP de escritura/lectura como variable de instalacion y para Django App (OMLApp) se pueden proporcionar ambas VIP de manera tal que cuando necesite hacer inserciones se utilice la VIP RW y para consultas la VIP RO.
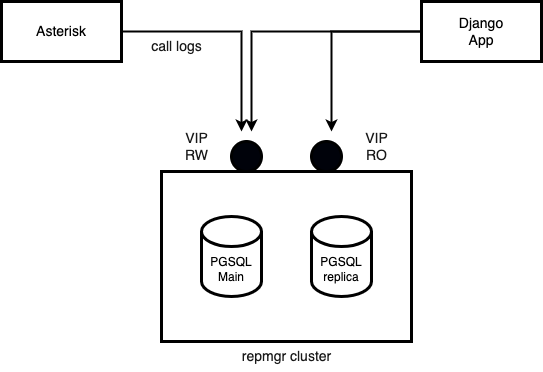
Entendido el concepto del cluster se puede avanzar con la instalacion de cada nodo. Para ello utilizar el script de deploy disponible en el repositorio:
curl https://gitlab.com/omnileads/omlpgsql/-/raw/master/deploy/first_boot_installer.tpl?inline=false > first_boot_installer.sh && chmod +x first_boot_installer.sh
En esta seccion solo vamos a poner enfasis en la variables de instalacion para HA. Ya que las demas estan explicadas en la seccion Deploy del componente PostgreSQL.
Descomentamos entonces todos los parametros de HA. Se deben considerar dos estructuras a la hora de plantear las variables de instalacion.
Por un lado cuando se despliaga el nodo main:
# Uncomment for HA
export oml_deploy_ha=true
# node role values: main | backup
export oml_ha_rol=main
# NIC to attach Virtual IP
export oml_ha_vip_nic=eth0
# Virtual IP for HA cluster read/write
export oml_ha_vip_main=172.16.20.65
# Virtual IP for HA cluster read only
export oml_ha_vip_backup=172.16.20.66
Y por otro lado tenemos a el nodo replica:
# Uncomment for HA
export oml_deploy_ha=true
# node role values: main | backup
export oml_ha_rol=backup
# NIC to attach Virtual IP
export oml_ha_vip_nic=eth0
# Virtual IP for HA cluster read/write
export oml_ha_vip_main=172.16.20.65
# Virtual IP for HA cluster read only
export oml_ha_vip_backup=172.16.20.66
Solo cambia dentro de la variable oml_ha_rol: backup por main a la hora de desplegar el nodo replica del cluster.
Nota
172.16.20.65 y 172.16.20.66 son tan solo IPs ejemplo. Estas son las direcciones IP virtuales que cada nodo va a apropiarse dependiendo de su rol y el estado del otro nodo.
Una vez ajustadas las variables, entonces se procede con el deploy de cada nodo del cluster.
Con ambos nodos disponibles, se debe proceder con una serie de pasos manuales de configuracion para dejar activo nuestro cluster:
En el nodo principal ejecutar:
main_pgsql$ systemctl start postgresql-11
main_pgsql$ su postgres -
main_pgsql$ cd ~
main_pgsql$ pg_basebackup -h $ip_main_node -U replicador -p 5432 -D basebackup -Fp -Xs -P -R
main_pgsql$ rsync -a basebackup/ root@$ip_replica_node:/var/lib/pgsql/11/data/
Importante
El parametro «$ip_main_node» e «$ip_replica_node» hacen referencia a las direcciones IP fisicas (NO virtuales) de cada nodo. Por otro lado, a la hora de efectuar el pg_basebackup se solicita un password, por lo tanto aqui se debe ingresar el mismo pasword asignado al usuario omnileads, proporcionado en el script de instalacion.
A continuacion se acciona nodo main en el cluster:
main_pgsql: repmgr -f repmgr.conf master register -F
Sobre el nodo de replica se deben ejecutar ahora una serie de comandos:
replica_pgsql$ systemctl stop postgresql-11
replica_pgsql$ su postgres -
replica_pgsql$ cd ~
replica_pgsql$ repmgr -h $ip_main_node -U repmgr -d repmgr -f repmgr.conf standby clone -F
replica_pgsql# systemctl start postgresql-11
replica_pgsql$ repmgr -f repmgr.conf standby register -F
Como ultimo paso, se deben reiniciar los servicios repmgr11 y omlpgsql-ha en AMBOS NODOS:
systemctl restart repmgr11
systemctl restart omlpgsql-ha
Comprobaciones luego de instalar:¶
- Estado de los servicios:
systemctl status postgresql-11
systemctl status repmgr11
systemctl status omlpgsql-ha
- Estado del cluster:
su postgres -
cd ~
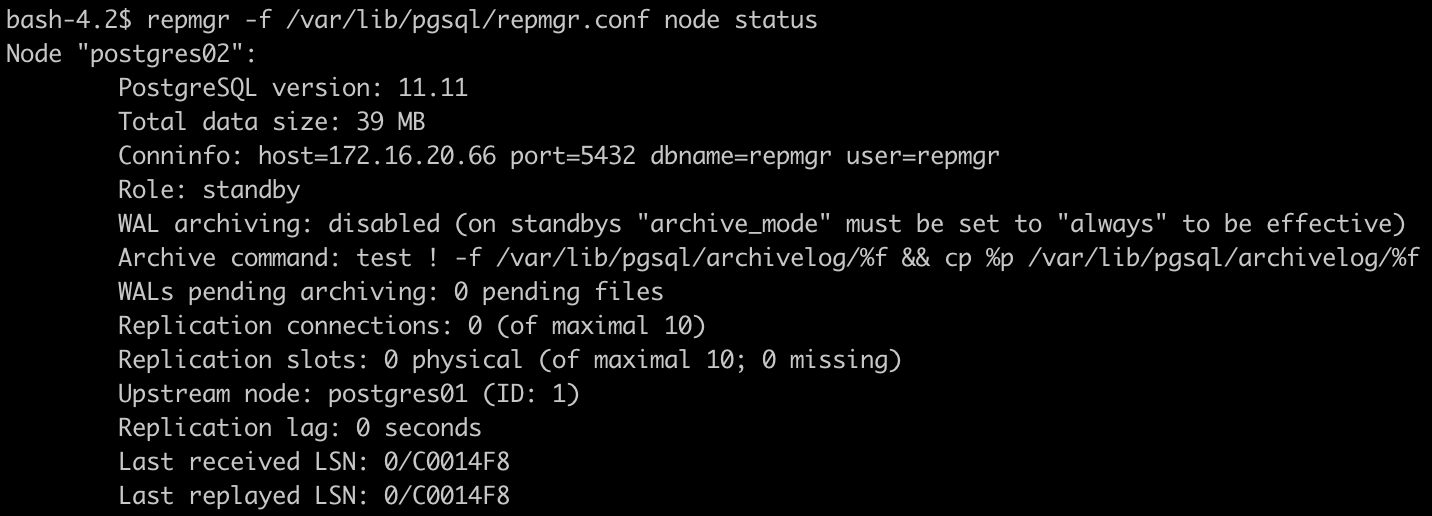
repmgr -f /var/lib/pgsql/repmgr.conf node status
Arrojando una salida similar a la siguiente imagen si se trata del nodo principal:

Mientras que en el nodo de replica:
- Direcciones IP virtuales: en cada nodo arrojar el comando ip a para comprobar la correcta asignacion de VIPs.
ip a
Un log muy importante para revisar es:
tail -f /var/log/repmgr/repmgrd.log
Donde queda expuesta la actividad sobre todo cuando cae alguno de los nodos.
Comprobación de PGSQL Failover¶
Para forzar un failover y comprobar si el cluster funciona, se puede proceder con el apagado del nodo main, observacion del log /var/log/repmgr/repmgrd.log y posterior interrogación sobre el ROL cada nodo.
Al estar en un escenario de datos SQL la recuperacion de un nodo frente a un Failover es un tanto mas compleja e implica un accionar manual del DBA/IT admin. Dicho procedimiento se detalla paso a paso: about_recovery_pgsql_ha.
Asterisk¶
La implementacion de Asterisk en modo cluster descansa sobre la tecnologia Keepalived. Se trata de un cluster mas sencillo, ya que Asterisk no implica que haya replicacion de datos. Simplemente se trata de una VIP (Virtual IP) manejada por Keepalived. Quien al detectar un fallo en el nodo Asterisk main se encarga de levantar la VIP sobre el nodo hasta entonces pasivo quien asume el rol de main.
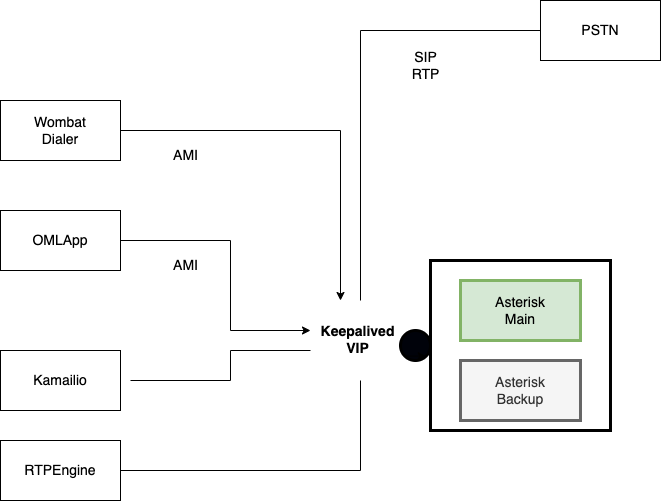
Por lo tanto todos los componentes que dialogan a nivel networking con Asterisk estarán interactuando en realidad a la IP Virtual establecida por el cluster-manager Keepalived.
Entendido el concepto del cluster se puede avanzar con la instalacion de cada nodo. Para ello utilizar el script de deploy disponible en el repositorio:
curl https://gitlab.com/omnileads/omlacd/-/raw/master/deploy/first_boot_installer.tpl?inline=false > first_boot_installer.sh && chmod +x first_boot_installer.sh
En esta seccion solo vamos a poner enfasis en la variables de instalacion para HA. Ya que las demas estan explicadas en la seccion Deploy del componente Asterisk.
Con respecto al despliegue del componente en cluster, se pone énfasis en las siguientes variables:
#### OMLApp netaddr
export oml_app_host=172.16.20.84
#### REDIS netaddr
export oml_redis_host=172.16.20.84
#### POSTGRESQL netaddr and port
export oml_pgsql_host=172.16.20.81
A la hora de declarar la direccion de los hosts: OMLApp, Redis y PGSQL se debe considerar utilizar las direcciones virtuales. Recordemos que para alcanzar a OMLApp y Redis se utiliza Haproxy, por lo tanto los dos parametros correspondientes deberan ser iniciados con la VIP de Haproxy. Para el caso de PosgreSQL se debe utilizar la VIP de RW del cluster.
##### Uncomment ALL for HA
export oml_deploy_ha=true
##### node role values: main | backup
export oml_ha_rol=
##### Virtual IP for HA cluster
export oml_ha_vip=
##### NIC for VIP eth0 enp0s3 wl01 ...
export oml_ha_vip_nic=
##### Tenant name
export oml_ha_tenant=
##### Email for failover notifications
export oml_ha_email=
Nota
Solo cambia dentro de la variable oml_ha_rol: backup por main a la hora de desplegar el nodo replica del cluster.
Comprobaciones luego de instalar:¶
Una vez disponibles ambos nodos podemos comprobar el estado de Keepalived.
systemctl status keepalived
tail -f /var/log/keepalive/keepalived.log
El nodo que este oficiando como main debera tener asociada la Virtual IP de Keepalived.
Comprobar el estado de cada nodo respecto a la VIP:
$ip a
Failover - Takeover¶
Para probar un failover simplemente puede apagar el nodo principal y al cabo de unos segundos el nodo de backup asumira la VIP. El procedimiento de takeover simplemente se lleva a cabo automaticamente cuando el nodo «inicialmente main» se vuelve dispible, por lo que la VIP vuelve a ser tomada por este ultimo.
HAProxy:¶
Este componente es utilizado por un lado a la hora de procesar y efectuar el balanceo de solicitudes HTTPS de los usuarios entre los nodos de aplicacion Web (Django/uwsgi), mientras que por el otro sirve de ayuda a los componentes OMLApp Django, Asterisk y Kamailio que son quienes requieren de conexión a Redis, pero a su vez declaran la direccion de red o IP de HAProxy en lugar de Redis, ya que este ultimo determina quien esta oficiando como nodo Redis principal y así deriva las conexiones hacia este mismo.
El cluster HAProxy esta basado tambien en Keepalived. Simplemente se trata de una VIP (Virtual IP) manejada por Keepalived. Quien al detectar un fallo en el nodo Haproxy main se encarga de levantar la VIP sobre el nodo hasta entonces pasivo quien asume el rol de main.
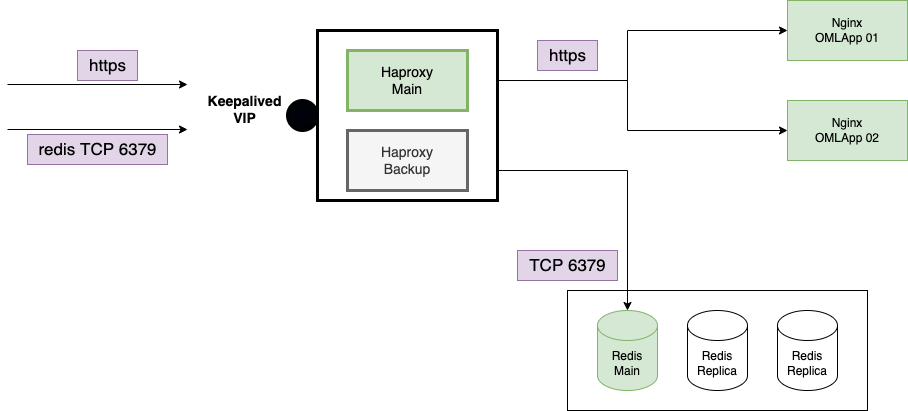
A la hora de ejecutar el deploy del componente, simplemente se debe obtener el script de instalacion y configurar las variables.
curl https://gitlab.com/omnileads/omlhaproxy/-/raw/main/deploy/first_boot_installer.tpl?inline=false > first_boot_installer.sh && chmod +x first_boot_installer.sh
Vamos a asumir ciertas direcciones IP de ejemplo.
# --- OMniLeads Web App nodes to add to cluster
export oml_app_01_host=172.16.20.71
export oml_app_02_host=172.16.20.72
# --- OMniLeads REDIS nodes to add to cluster
export oml_redis_01_host=172.16.20.61
export oml_redis_02_host=172.16.20.62
export oml_redis_03_host=172.16.20.63
export oml_redis_04_host=172.16.20.64
export oml_haproxy_branch=main
# # Set your net interfaces, you must have at least a PRIVATE_NIC (eth0, enp0s3 ...)
export oml_nic=eth0
# export oml_deploy_ha=true
# node role values: main | backup
export oml_ha_rol=main
# --- The Virtual IP address
export oml_ha_vip=172.16.20.84
# --- The Network interface NIC for Virtual Public or Private IP addr (eth0, enp0s3 ...)
export oml_ha_vip_nic=eth0
# --- Tenant name
export oml_ha_tenant=omnileads.example
# --- Email to send notification in case of fails
export oml_ha_email=notifications@domain.com
Nota
La unica diferencia a la hora de deplesgar el nodo main y backup es la variable oml_ha_rol.
Importante
Si desea cifrar HTTP con su propio certificado SSL, debera crear la carpeta certs en la misma ubicacion donde descargo el script de instalacion. El archivo debera nombrarse como hap.pem. En caso de contar con los archivos «.crt» y «».key» se deberan fusionar en uno mismo:
$cat oml.crt oml.key > hap.pem
Comprobaciones luego de instalar:¶
Una vez disponibles ambos nodos podemos comprobar el estado de Keepalived.
systemctl status keepalived
tail -f /var/log/keepalive/keepalived.log
El nodo que este oficiando como main debera tener asociada la Virtual IP de Keepalived.
Comprobar el estado de cada nodo respecto a la VIP:
$ip a
Failover - Takeover¶
Para probar un failover simplemente puede apagar el nodo principal y al cabo de unos segundos el nodo de backup asumira la VIP. El procedimiento de takeover simplemente se lleva a cabo automaticamente cuando el nodo «inicialmente main» se vuelve dispible, por lo que la VIP vuelve a ser tomada por este ultimo.
Nginx, Kamailio, RTPengine, websockets y Django/UWSGI:¶
Bajo el actual esquema de HA, los componentes Nginx, Kamailio, RTPengine, websockets y Djano/uwsgi comparten el mismo linux host. Por lo tanto existirán dos instancias linux corriendo exactamente la misma configuracion de OMniLeads y los demas componentes. Al existir HAproxy como balanceador de carga entonces ambos nodos trabajaran como un cluster Activo-Activo, procesando las peticiones a partir del balanceo que se haga en la etapa pertinente.
Los componentes en cuestión se deben desplegar en dos instancias de Linux, tal como si fuese una instalación basada en cluster común y corriente. Ya que HAproxy se encarga de hacer el balanceo de las solicitudes HTTPS entre los dos nodos implicados.
Entendido el concepto del cluster se puede avanzar con la instalacion de cada nodo. Para ello utilizar el script de deploy disponible en el repositorio:
curl https://gitlab.com/omnileads/ominicontacto/-/raw/master/install/onpremise/deploy/ansible/first_boot_installer.tpl?inline=false > first_boot_installer.sh && chmod +x first_boot_installer.sh
En esta seccion solo vamos a poner enfasis en la variables de instalacion para HA. Ya que las demas estan explicadas en la seccion about_install_linux.
Con respecto al despliegue del componente en cluster, se pone énfasis en las siguientes variables:
export oml_redis_host=
export oml_acd_host=
export oml_psql_host=
export oml_redis_ha=true
export oml_sentinel_host_01=
export oml_sentinel_host_02=
export oml_sentinel_host_03=
Utilizando las direcciones IP VIRTUALES adjudicadas a cada cluster de los componentes aquí referenciados. Respecto a las variables oml_sentinel_host, se debe considerar que hace referencia a los tres nodos de replica que implican a sentinel.
Nota
Para acceder a la aplicacion debera hacerlo invocando el hostname o VIP de haproxy.
Comprobaciones luego de instalar:¶
Una vez disponibles ambos nodos podemos comenzar a loguear usuarios y observar (mediante el analisis del log: /var/log/nginx/example_access.log) en cada nodo, como van llegando solicitudes de manera balanceada entre ambos nodos.
Aqui no vamos a hablar de Failover o Takeover, ya que HAproxy nos abstrae del asunto. Simplemente si un nodo de estes cae, entonces el proxy hara el balanceo sobre el que quedo disponible. Luego si el nodo regresa operativo, entonces se volvera a balancear sobre dich nodo.